家計調査から見える、その街の特徴
「この街は、どんな暮らし方をしている人が多いのか?」
地域のことを知りたいとき、皆さんはどのような情報を集めますか?
市役所のHPを見たり、Wikipediaを見たり、地図を開いたり、人口や人口動態を眺めたり…様々な調べ方があるかと思います。今回は、そんな一般的な情報収集とは少し違う角度から街を見る方法をとってみたいと思います。それが「家計調査」です。
家計調査は、都市ごとの消費スタイル・生活スタイルの違いを「各家庭の消費額」の視点からまとめられた公的データです。
この記事では、次の3つのステップで家計調査を整理したいと思います。
- 家計調査とは何か
- 家計調査の特徴を知る
- 家計調査のデータを触ってみる
家計調査とは何か
家計調査は、総務省統計局が実施する調査です。国の重要な統計調査として、統計法に基づく基幹統計調査に指定されています。特に、毎年2月に公表される自治体別・品目別の調査結果はメディアでも頻繁に取り上げられ、まちおこしの話題としても注目されています。「餃子の消費額一位は宇都宮!浜松!宮崎!」などの報道を耳にしたことがある方もいらっしゃるかと思います。その根拠がこの調査結果です。
押さえておきたいポイントは、次の3つです。
- 対象:全国約9,000世帯(個人単位ではない)
- 内容:家計の収入・支出、貯蓄・負債など
- 範囲:全国168自治体(都道府県庁所在地・政令指定都都のすべてと、一部の市区町村)
- 時期:毎月調査。毎年2月には自治体別・品目別の調査結果が公表される。
なお、対象世帯の選定には層化3段抽出法と呼ばれる手法が用いられており、市町村・単位区・世帯の順で3段階の無作為抽出を行い、対象世帯の絞り込みが行われます。また、調査対象は定期的に入れ替えられ、特定の世帯が継続して調査されない仕組みとなっています。
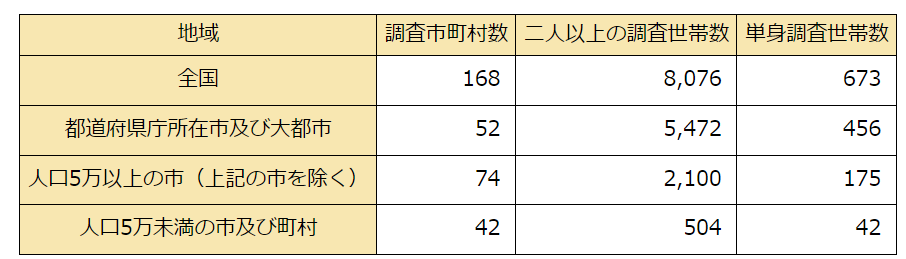
※画像引用及び家計調査の調査対象の詳細は総務省統計局ホームページを参照(https://www.stat.go.jp/data/kakei/1.html)
日本の家計収支の実態を把握するための重要な基礎データとなっています。
家計調査の特徴を知る
家計調査を見ると、次のような傾向が浮かび上がってきます。
- 消費の優先順位:食費にお金をかける街、外食が多い街、教育費が高い街
- 生活の利便性:交通費が高い、光熱費が高い
- その街の特徴的な消費:餃子の消費額が多い、饅頭の消費が多い
特に、その街の特徴的な消費については、冒頭でも触れたとおり、毎年2月に結果が公表されると、ほぼ必ずメディアで取り上げられ、町おこしの題材として大きな盛り上がりを見せます。
一方で、家計調査の結果のみでその街の消費の特徴を説明する際には、やや注意が必要です。家計調査は、日本全体の家計収支の実態を把握する重要な統計である一方、調査対象は168自治体、調査世帯数も全国で約9,000世帯に限られています。全国には1,700を超える自治体があることを考えると、本調査では特徴を十分に捉えきれていない自治体が存在する可能性があります。
また、1自治体あたりの調査世帯数は平均すると約50世帯程度と少なく、一部の世帯による高額消費が結果に大きな影響を与える場合があります。また、家電製品や住宅関連工事費など、もともと支出頻度が低い品目では、単発の支出による影響が大きくなりがちです。
このため、市区町村別の結果はメディアで多く報じられているものの、細かく分解して見ると年ごとのばらつきが大きい点には留意が必要です。昨年は全国で突出して消費額が多かった品目が、翌年には目立たなくなる、あるいはこれまで他都市並みだった品目が急に注目されるといったことは、決して珍しくありません。
それでもなお、家計調査は毎年、町おこしの観点からも大きな関心を集めており、統計を身近に感じる貴重な機会であることもまた事実です。
家計調査データを、実際に触ってみる
ここまで来ると、「考え方は分かったけど、実データはどう見るの?」と思われた方もいらっしゃるのではないでしょうか。
実は家計調査は、少し手を動かすだけで自分の街を切り口にデータを見ることができます。
今回は Pythonを使ってデータを取得し、簡単な集計まで行ってみます。話題性のある市区町村別の集計を題材にします。
なお、「いきなりPythonでコードを書くのはちょっと……」という方は、e-Stat(政府統計ポータル)からデータを直接ダウンロードすることも可能です。こちらについても、いずれ別の記事で紹介する予定です。
e-Stat 家計調査(直接ダウンロードする場合)
https://www.e-stat.go.jp/stat-search/files?page=1&toukei=00200561&tstat=000000330001
今回やること
- 家計調査データを Googleスプレッドシート に取り込む
- Pythonを使って「特定の街で、支出上位に入っている品目」を抽出する
ギョーザといえば浜松や宇都宮。では、自分の街では何にお金が使われているのか?
それを実際に見てみましょう。今回は例として山口市を扱いたいと思います。
Pythonでの簡単な処理例
import pandas as pd
##関数を定義
def find_top_items_rank_and_price(sheet_url, city='山口市', top_n=6):
# スプレッドシートを読み込み
csv_export_url = sheet_url.replace('/edit?usp=sharing', '/export?format=csv&gid=0')
data = pd.read_csv(csv_export_url)
# 結果格納用のリスト
top_items_rank_and_price = []
# 各品目についてループ処理
for item in data.columns[1:]:
# 品目ごとにデータをソート
sorted_data = data.sort_values(by=item, ascending=False).reset_index(drop=True)
# 指定された市区町村が指定された上位N位以内か確認し、順位と金額を取得
city_row = sorted_data[sorted_data['市区町村'] == city]
if not city_row.empty and city in sorted_data.iloc[:top_n]['市区町村'].values:
rank = sorted_data.index[sorted_data['市区町村'] == city].tolist()[0] + 1
price = city_row[item].values[0] # 指定された市区町村の金額を取得
top_items_rank_and_price.append([item, rank, price])
# 結果をDataFrameに変換しソート('順位'で昇順に、次に'金額'で降順に)
top_items_rank_and_price_df = pd.DataFrame(top_items_rank_and_price, columns=['品目', '順位', '金額'])
top_items_rank_and_price_df_sorted = top_items_rank_and_price_df.sort_values(by=['順位','金額'], ascending=[True, False])
return top_items_rank_and_price_df_sorted
#関数を実行
#まずは3つの変数を指定
city = '山口市'
top_n = 3
sheet_url = 'https://docs.google.com/spreadsheets/d/1wQFZ-Rh_f2OsQwZIlNTJ8ca-0MbJmqFZ9FrnuIq20OI/edit?usp=sharing'
# 結果を取得
top_items_rank_and_price = find_top_items_rank_and_price(sheet_url, city=city, top_n=top_n)
print(top_items_rank_and_price)
スプレッドシートのURLを差し替えるだけで、
年度や調査内容を変えて同じことができます。
見えてきたこと(例)
例えば山口市では、
- 干しのり
- あじ
- 海産物関連
といった品目が上位に出てきました。三方を海に囲まれた地域性が、支出という形で表れていると読めます。一方で、「給排水関係工事費」のような項目が上位に来ることもあります。これは、たまたま調査対象世帯がリフォームをしていた可能性が疑われ、数字をそのまま受け取らない視点が必要です。
地域データを読む最初の一歩として、家計調査はとても使いやすいデータだと思います。
家計調査は、その対象が県庁所在地や政令指定都市に限られており、調査対象世帯も限定されているため、特に支出頻度が低い項目(家電製品や工事費用など)に関しては結果のばらつきが大きいことに注意が必要です。しかし、この調査は毎年、まちおこしの観点からも大きな関心を集めています。
生活に密接な統計データとして、みなさんもぜひデータを触ってみましょう!
こ